

Subscribing is a smart move!
You can subscribe to this board after you log in or create your free account.
EcoStruxure IT forum
Schneider Electric support forum about installation and configuration for DCIM including EcoStruxure IT Expert, IT Advisor, Data Center Expert, and NetBotz
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:04 PM . Last Modified: 2024-04-09 11:59 PM
Hello,
After running a Server Utilization report I get the following;
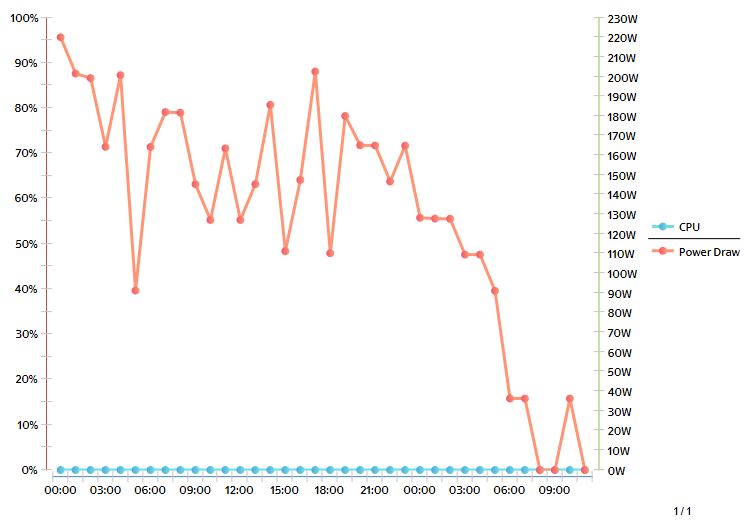
However when I look on the server I get the following report;
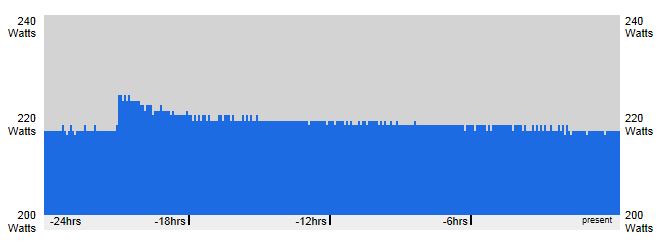
And on DCM I get,

which seems to relate to the server.
Why is the report run in DCO so different to what is actually reported? All graphs are over a 24 hour period.
(CID:96043899)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:04 PM . Last Modified: 2024-04-09 11:59 PM
Hi James, We are currently investigating. Would it be possible to share a little more detail on the device discovered? Also just to be sure the time interval is the same across the graphs?
(CID:96043946)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:04 PM . Last Modified: 2024-04-09 11:59 PM
It was a HP DL380 Gen9 via the iLO (IPMI). The server utilisation report from DCO was a daily and the two other reports was the previous 24 hours.
(CID:96043962)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:04 PM . Last Modified: 2024-04-09 11:59 PM
Hi James, We have investigated further. However the next step would be to look deeper into your setup. If possible could you share a backup of your system for us to investigate further in detail? Also please share log files capture via the server configuration/Webmin interface I've invited you to a box folder where files can be uploaded. Please let me know if this will work for you otherwise we could do a remote login to your system and troubleshoot from there. What ever you fint the easiest.
(CID:96044105)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:04 PM . Last Modified: 2024-04-09 11:59 PM
Søren - I have added the files as requested.
(CID:96044142)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:04 PM . Last Modified: 2024-04-09 11:59 PM
Hi James, We have received your files and are currently investigating them.
(CID:96044157)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:59 PM
Hello James. Thank you for sharing the log and database information. The data polled by DCM agrees with the non server utilization screenshots you attached to this community thread, but the data actually being logged to ITO was near zero in some cases. Your log files show a number of occasions where ITO reported a "GC Overhead limit" error (also in one of your screenshots) which means the ITO service was running out of memory. Given the error is occurring during IT Optimize polling cycles its likely this condition is tied to this behavior. If you were to view the contents of your IT Optimize installation folder (on the ITO server) you will find files named something like java_pidxxxxx.hprof. If possible, can you upload the newest .hprof file to the box folder so we can analyze the memory dump and understand the cause in more detail? I think we know why. I have pasted a procedure below to change the polling threads used but ITO so it will consume less memory. Their polling time is taking between 3 and 4 minutes to complete and given their server has 2 allocated CPU's I'm guessing its busy most of the time. Wouldn't be a bad idea to tell the customer to change their polling interval to every 10 minutes or every 15 minutes as well. This change can be made by editing the external system definition for the ITO server. If they plan to dramatically increase the number of discovered devices well beyond 500 devices (most of which being IPMI based) I would suggest increasing the number of allocated CPU's to the ITO server to four cpu's. Changing the number of assets ITO will attempt to simultaneously poll. * Logon to the IT Optimize server as an administrator user. * Change to the IT Optimize installation folder. By default this would be: C:\Program Files\SchneiderElectric\ITOptimize\, but this destination folder can be changed during installation, so change to the proper location. * In the "bin" sub-folder (so the full path would be C:\Program Files\SchneiderElectric\ITOptimize\bin), you'll find a file called "EnergyCenter.ini". * Edit the EnergyCenter.ini file. The top set of lines in this file will look like this (pasted in red below). There are more lines, I'm only showing the top of the file. service.class=com.viridity.dcos.server.ViridityServer service.id=EnergyCenter service.name=Schneider Electric EnergyCenter service.description=Data Center Energy Management Software service.startup=auto service.controls=stop|shutdown process.priority=high single.instance=process working.directory=C:\PROGRA~1\SCHNEI~1\ITOPTI~1 vm.location=java\bin\server\jvm.dll vm.version.min=1.6 vm.version.max=1.6 vmarg.1=-Xms128m vmarg.2=-Xmx1024m vmarg.3=-server vmarg.4=-Djava.library.path=lib vmarg.5=-Dviridity.dcos.home=C:\PROGRA~1\SCHNEI~1\ITOPTI~1 vmarg.6=-Dcom.sun.management.jmxremote.port=3333 vmarg.7=-Dcom.sun.management.jmxremote.ssl=false vmarg.8=-Dcom.sun.management.jmxremote.authenticate=false vmarg.9=-XX:+HeapDumpOnOutOfMemoryError vmarg.10=-XX:MaxPermSize=256m vmarg.11=-Xrs Immediately after the line "vmarg.11=Xrs", add this line: vmarg.12=-Dviridity.threadpool.poller.size=15 Save the file, and restart the IT Optimize service. To restart the service: * Open the windows services control panel * Right click on the 'schneider electric energy center' service and choose restart. Only this service needs to be restarted, the 'schneider electric energy center database' service does not need to be restarted. Regards Greg Sterling
(CID:96044562)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:59 PM
Greg, I have copied the files you requested to the share and changed the polling time to 30 minutes. What exactly does the vmarg.12=-Dviridity.threadpool.poller.size=15 command change?
(CID:96044565)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:59 PM
Hi James, To my understanding it will change the number of assets ITO will attempt to simultaneously poll. This will have an impact on the consumed memory on the ITO machine.
(CID:96044567)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:59 PM
Hello James Soeren is correct regarding the change we sent you regarding the "vmarg.12" argument. This item reduces the number of objects ITO attempt to poll simultaneously. This change will dramatically reduce the memory footprint consumed during the polling cycle. Thank you for uploading the hprof file. The file analysis was completed on Friday, it seems the quantity of cached data during polling is consuming a lot of memory. The change we sent you should help reduce the chances of recreating the issue. Engineering will investigate more efficient methods for caching the previous poll data to permanently address this problem (so the polling thread count does not need to be reduced). The improved caching will be targeted for a future release.
(CID:96044569)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:59 PM
Hello again James. I meant to add, its extremely likely the polling cache space issue mentioned in the above comment directly lead to zero power readings being recorded in the ITO database for some assets, thus leading to the power drop you experienced in the server utilization report. If the thread poller change was applied and the ITO service restarted, I'd expect you're are seeing more accurate power data in the server utilization report now. Regards Greg Sterling
(CID:96044571)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:59 PM
Greg/Søren, I have applied the changes as requested and increased the polling time. I will let the system collect some data before posting back on how it went
(CID:96044573)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:58 PM
Great. Thanks.
(CID:96044575)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:58 PM
James and Greg, I transitioned a comment into an answer and moved the related comments to the answer. From our investigation on this topic it is currently the answer to the question asked as I read the thread. Sorry for spamming you with emails related to this thread (and now once again ;-))
(CID:96044589)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:05 PM . Last Modified: 2024-04-09 11:58 PM
Greg/Søren I have check the graphs again and everything seems to be running as it should with both of them matching. I will keep an eye on it and let you know if anything happens. I look forward to the improvement on future releases. Thanks for your help on this.
(CID:96044765)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2024-04-09 11:58 PM
Greg/Søren,
This error has started to happen again, below are two screen shots of the same server over a one week period, as you can see DCO is reporting almost constant 0W reading whereas the real reading is closer to 319W
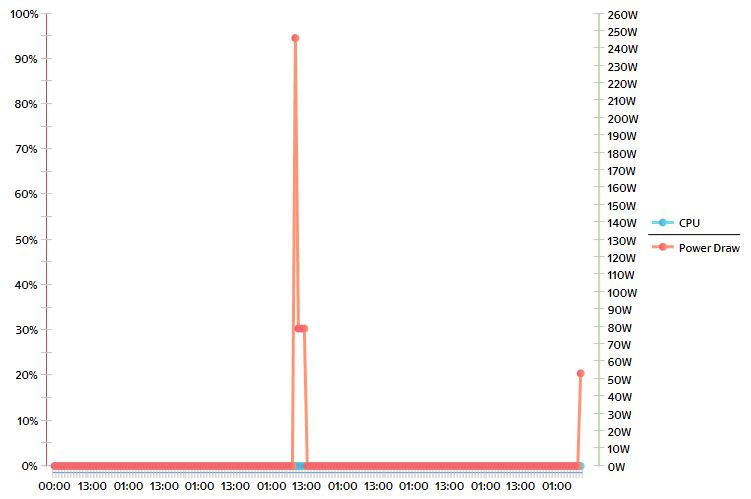

(CID:96764531)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2024-04-09 11:58 PM
James Please re-collect ITO logs, and if a recent java_pidxxxxx.hprof file has been created in the ITO install folder please upload it to the box folder we previously used. https://schneider-electric.box.com/s/88eb4wxafcprpqzjt8xqyiinp9opqspf
(CID:96764683)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2024-04-09 11:58 PM
Greg, I have added the logs and a backup. The hprof file has not been updated since the last error so I did not include it.
(CID:96764816)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2024-04-09 11:58 PM
Great. Thanks. I will check out the logs.
(CID:96764820)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2024-04-09 11:58 PM
posting on behalf of Greg Sterling : James, do you have the IP address of one or more of the hosts experiencing this issue? I will attempt to identify which assets are at-play when I restore the database. There are a set of mgmt cards which are starting their username/password creds changed... is it possible the username/password used to originally discover some of these assets over IPMI changed? BTW, there were more IP's, it takes some time to extract them from the log files.
(CID:96765113)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2024-04-09 11:58 PM
Greg/Søren, I have emailed you over a couple of IP addresses. There will be a number of card that have had their credentials changed so I am expecting that.
(CID:96765169)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-02 12:06 PM . Last Modified: 2023-10-31 10:54 PM

This question is closed for comments. You're welcome to start a new topic if you have further comments on this issue.
Link copied. Please paste this link to share this article on your social media post.
Create your free account or log in to subscribe to the board - and gain access to more than 10,000+ support articles along with insights from experts and peers.