
Ask our Experts
Didn't find what you are looking for? Ask our experts!
Schneider Electric support forum about installation and configuration for DCIM including EcoStruxure IT Expert, IT Advisor, Data Center Expert, and NetBotz
Search in
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 06:47 PM . Last Modified: 2024-04-07 11:44 PM
Hello Steve.
I have started a new thread on this as we discussed.
Ok what seems to occur is as follows:
What seems to happen is when VM Disk Consolidation occurs, comms are reset & users are dropped. We are running DCE 7.4.2 & our client PC sits in the same Network as the DCE VM. Prior to this problem, our DCE was randomly freezing/locking up/ being unresponsive & you could not log in. A Software or VM reboot was required to return its functionality. Our VM Support staff ran some config as they believe that the VM Disk Consolidation was failing & the config was meant to fix this issue. It did but we then got the new issue of comms/users dropping.
At a VM level, the VMWare is not happy with its health so it tries to reset everything, so CPU use, disk usage, comms goes down to the point that users are ejected from the Client Software. Users can log back into DCE with no issue afterwards.
Our VM Support team have referred the matter to VMWare Support for assistance but they have asked if we can install VM Tools on the server & they are not sure on this as they believe it is running open VM tools.
Please advise?
(CID:123346343)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 06:47 PM . Last Modified: 2024-04-07 11:44 PM
Hi Jeff,
Let's get some info on the DCE server.
What have you provided for resources? How many drives, size, NICs, processors, etc.
What is listed under system --> storage settings for repositories, usage, etc? Purge settings?
How many nodes are being monitored?
Are you using surveillance and if so, how many cameras and how often are surveillance images being captured?
How often does the system run backups and when?
Are you using StruxureWare DCO (operations) in conjunction with DCE or the web API in any way?
Are you connecting via HTTP or HTTPS?
As for the VM side of things:
Is the storage physically connected to the server or is it using a network share?
I know that VM tools are installed but I do not know the version info. I can get that if necessary. Other than what is installed already, we don't allow anything else to be installed on the system.
If you can get info on when specifically these issues have occurred, we can see if the server's logs show any detail. Do you know if all clients have the issues at the same time or if it is specific to one client or another?
You can download the logs on the client at C:\Users\
Thanks,
Steve.
(CID:123346812)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 06:47 PM . Last Modified: 2024-04-07 11:44 PM
Hi Steve. Sorry for the delay in replying. It seems the VM people are working on their fix which at this point seems to be locking out the Disk Consolidation process & to date we have had no negative impact at ISX level & it has cured our log out issues. I'm not very confident as this also stops our daily Avamar disk image backup from running. Anyway to answer your questions:
What have you provided for resources? How many drives, size, NICs, processors, etc.
2 X Hard Disks, 250GB & 18GB, 2 X Nics, 2 X Processors
What is listed under system --> storage settings for repositories, usage, etc? Purge settings? Local repository has capacity of 237.63GB & we are using 48.37GB or 20.35%
How many nodes are being monitored? We have a total of 2226 devices including Virtuals
Are you using surveillance and if so, how many cameras and how often are surveillance images being captured? No cameras connected
How often does the system run backups and when? We run a manual backup once a week.
Are you using StruxureWare DCO (operations) in conjunction with DCE or the web API in any way? No we only have DCE & we use it via the Client software installed on PC's sitting in the Network. No Firewall traversing required.
Are you connecting via HTTP or HTTPS? We use the CLient Software to connect.
Is the storage physically connected to the server or is it using a network share? The Storage is physically connected, no Network Share.
Do you know if all clients have the issues at the same time or if it is specific to one client or another? When the Clients are logged out, they are all logged out at once.
I've attached the log as requested.log
Thanks.
(CID:123348891)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 06:47 PM . Last Modified: 2024-04-07 11:44 PM
Hi Jeff,
There's definitely an issue with performance at least. There's messages all over the place like this:
!ENTRY com.apc.isxc.logging 2 0 2017-07-04 23:23:29.399
!MESSAGE Have not processed an event within 170157 milliseconds. UI Performance is at risk.
!ENTRY com.apc.isxc.logging 2 0 2017-07-04 23:23:34.399
!MESSAGE Have not processed an event within 175157 milliseconds. UI Performance is at risk.
That could be the server or network or even client but most likely server. Can't say it's resource related but with 2226 devices, you may want more. The VM guidelines say 2 gig and 2 processors for up to 2000 nodes but you're a little above and it couldn't hurt in the case of a potential resource issue.
What do you have for RAM?
You noted 2 NICs. How are they set up? Do they both go to the same network or networks that are totally separated?
Client software can connect to DCE using HTTP or HTTPS. You can usually tell by port but there's more under advanced:
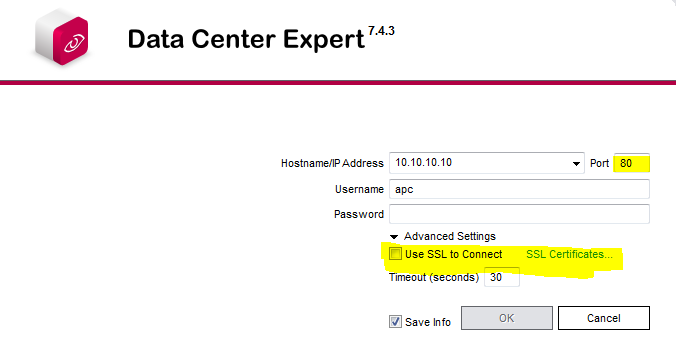
Maybe we need to see the server logs. They're available on the server's web page:
http://
If a file exists, delete it. Create a new archive.
So that I can know where to look in the log, please provide some dates and times the issue occurred prior to creating the log archive.
It may be pretty big so you may have to put it on a box folder. It will also have some IP info so if you feel that's sensitive info, continuing to post here may not be the best bet. Calling into the queue may also be faster.
Steve
(CID:123349408)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 06:48 PM . Last Modified: 2024-04-07 11:44 PM
Hi Steve.
We have 2 X gigs of Ram & we are only using the standard client setup via Port 80 so just HTTP. While we have 2 X NIC's, we are only using 1 & we don't use the second one at all. Do you think we would get any advantage from setting up & using the second NIC? If so, is there some doco on it?
I wont send the logs just yet as the VM Support group think they have solved the problem so we are monitoring to see what happens. At this stage, they believe that the issue was caused by the backups not releasing the disk and causing the failover attempts.
Here is their comment: "
This morning we attempted a consolidation of the Struxureware disks which failed due to disk locking. This was caused by the Back up disk having a lock over the disk and it was mounted on that server. We have shut down the back up disk and unmounted the disk from that server.
Done a consolidation of the disks successfully. We have done a storage vmotion which also does a consolidation. Also moved the server to a new host to see how we go also.
All good so far.
Jeff.
(CID:123349556)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 06:48 PM . Last Modified: 2024-04-07 11:44 PM
Hi Jeff,
Since the 2 NICs must be on different LANs, no I do not think using the 2nd one would help. I simply wanted to find out if it was in use and see if you were trying to use it on the same network segment as this could also cause performance issues. Let me know if the move helps.
Steve
(CID:123349800)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:33 PM . Last Modified: 2024-04-07 11:44 PM
Hi Steven.
Our VM support have finished their part & all seems to be functioning on the VM side. On the DCE side, it is only ejecting users every second night which is a bit weird & last night, it ejected the 3 users as follows: 1 at 7:34pm, one at 7:38pm & the last one at 7:39pm. This is the first time like this as it usually ejects all users at once.
Just prior to this the VM recorded a "'vSphere HA virtual machine monitoring error" & "Virtual machine high availability error". This was about an hour after all the shapshots & disk consolidation was complete. I have the VM support team investigating.
(CID:123996894)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:33 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
The timing is a little strange but if it's happening around the time of the work benig done on the system, I'd be curious to know (if possible) how DCE would react if you don't do snapshots etc for a few days.
Steve
(CID:123997305)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:33 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steven.
Last night the DCE became unresponsive to users & a reboot was required to be performed at 9:54pm after exhausting all other avenues. I have enclosed a copy of last night's log & I did look at both the Tasks & Events log for the VM & there are no errors. According to VM support, when a VM is performing a consolidation it stuns the VM at the very end of the process to complete the consolidation or snapshot removal. If the server is generating data faster than the consolidation and stun timeout this may cause the server to become unresponsive.
In response to your last question, when the disk was locked out last week & no disk consolidation nor snapshots were being performed, the DCE worked fine with no issues. It just seems to me that whenever background tasks are performed, the DCE plays up.
We are again stuck in the middle here were we can't get definitive answers from the DCE side & the VM side. Why are these issues so difficult to diagnose & cure?
Also in my fault finding, we have a lot of Virtual sensors, could they be impacting our system?
Here is last night's log. ISX-DCE log 23 Aug 2017.docx
(CID:123997419)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:33 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
If the server itself had to be rebooted, the server logs will be needed.
http://
The client logs will only tell about the connection to the server. Maybe contacting us by phone would also make for a more speedy experience.
Steve
(CID:123997655)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:33 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steven. I'm not really concerned about speedy experience just a resolution & I think to try to explain this all over again would be an issue. Here is my capture log, hope it all uploads.
aqgwvc02.cems.citec.com.au_2017-08-25_11-45-53.tar.gz
(CID:123997871)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
If you look at the NBC.xml archives, you'll see one almost every day, sometimes 2 a day:
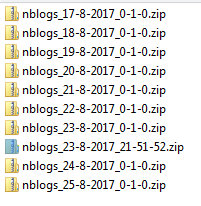
These are created when the server reboots or when the file reaches a pre-set limit. These all appear to be a reboot as they all start with events including:
I also noticed that in my download of your logs, those nbc.xml files which should all be different, are actually the same for the most part. I went back 5 versions and starting at the 22nd and going back, they all seemed to start with the same date code. Strange, they should be different. I'm wondering if the VMhost somehow stopping and restarting the system when creating a snapshot? Maybe an issue, maybe not. Do they look different if you look at the download directly (maybe something to do with the download?)
\data\logs\archive\
Looking for specific errors, I had to go back to the 23rd to find an NBC.XML file that wasn't just a reboot. I see a number of exceptions based on a device at 10.1.145.145. Not sure that's relevant to this issue though. I've seen numerous issues with polling devices but it is many different devices.
It also looks like you're using RMS. There seem to be no real errors but that can cause more comm and if there are any bandwidth errors, RMS can increase that.
Looking at the messages log, I can see that the server was rebooted around Aug 23 21:50:.
I see a lot of errors that although I am unfamiliar with, seem to repeat and if you're not getting logged off every 10 minutes or so, should not be the cause of the issue. Most of these having to do with graphing or scanning.
Prior to this, I did see numerous events on Aug 23 18:27. Did the issue occur at this time? There was a hung process and I see that the process was restarted. I found a similar group of messages at Aug 22 19:06. This happened a few times in a row and is close to the 7:34pm, one at 7:38pm & the last one at 7:39pm issue you had mentioned.
This last one looks like a smoking gun but I'll have to see if I can get more info as to why the process may have hung. I'll let you know what I find out.
Steve
(CID:123998119)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
Spoke to engineering on this and the first thing they stated was:
"They are not allocating enough resources to this appliance based upon the resource info I see in the log captures.
I can see that the load and wait averages are a bit too high and the server is into using swap memory. I also can see from the client log that on many occasions the client is not getting events from the server in a timely manner. This is typically caused when the server is bogged down processing data and cannot service client requests in a timely manner -> which is evident in the client logs.
I would advise them to increase the amount of RAM on the VM and also consider dedicating these resources (Thick provision) if they are not doing so already."
They also noted:
" The translate daemon is timing out and restarting often as you noted in the log"
"This translate daemon is used to translate language text for alarms / ddfs / etc.
Perhaps they are using several clients set to different language preferences? Please find out how they are using these settings in both the client and the server (for like alert settings, etc) "
Steve
(CID:123998160)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steve.
We have 3 clients logged in most days & they are all set on OS Locale for the language settings. The PC's that the clients are loaded on are all set to local locations/language ie Brisbane, Australia/English.
The VM is already set to 'Thick Provision'. We are still looking into possibly upping the RAM resources & we shall see what happens then.
Jeff.
(CID:123998388)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steven. We upped the Resources the other night after a 'lock up/freeze' of the server to 4 X CPU's & 4 GB's of Ram. We have had no Comms drop outs or lock ups since but we still get at least a line of 'performance' type issues every night that doesn't seem to affect anything. Last night we seemed to get several instances of "Failing to execute runable" errors but again no issues from it. We will keep monitoring over the next week or so to see what happens.
Thanks Jeff.
(CID:124521279)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
Can't say what that error may be off-hand but not all errors are something that will cause issues...it's why we don't usually point customers to these logs unless we need to. If the system has been running OK since the increased resources that's a good sign. Let me know if the issue returns and we'll look at it again.
Steve
(CID:124521484)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steve. Been running fine now all week with the extra resources with no kick outs or reboots required. Backups working fine as well. Can close this one now.
Thanks for you help.
Jeff Harrold
(CID:124522505)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steve. Spoke too soon. Had to reset the server last night as it became unresponsive & new log ins would fail. Everything at the VM level operated with no issues or errors. So now that we have upped the resources & we are still getting this issue. What is the next course of action? Is this unique to us?
(CID:124523178)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
Yes, this is something specific to your install or environment. So just to be sure, this used to happen every 2 days but after upping the resources, lasted almost a week? Did you get new logs? If not, can you please wait till it happens again, delete the old capturelogs, then create new logs before you reboot?
Steve
(CID:124523713)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:34 PM . Last Modified: 2024-04-07 11:43 PM
Ok, so we are no longer having users ejected since updating the resources. While it didn't happen every 2 days, yes the server becomes unresponsive, & it you try to log in via the webpage, you get a continual spinning wheel logo. Hence it is not possible to log in & get the logs before you reboot. This happened for the first time since the extra resources on Monday night, date 7 Sept 2017, started approx 1900 hrs & we rebooted approx 2100 hrs. I have enclosed the latest logs.aqgwvc02.cems.citec.com.au_2017-09-07_09-51-57.tar.gz
(CID:124524055)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:35 PM . Last Modified: 2024-04-07 11:43 PM
Hi Jeff,
What exactly did you reboot, server or client? I checked the last NBC.XML file and it should start after an archive or reboot. It started on Tuesday, September 5, 2017 5:58:46.228 AM (my time zone) and ended Wednesday, September 6, 2017 7:51:26.851 PM. I should see a new file after a reboot on 9/7 if these logs were obtained after a reboot. Messages log shows no reboot since 9/5/17.
The top_output file shows no real issue with memory or load but again, assuming this is taken during a time period with no issue, the file wouldn't show the worst of it.
Looking at the backup logs, I don't see a backup happening specifically but the ones that are listed, working or not, appear to happen around 9:00. Assuming this is 9:00 AM and not 21:00, the backup shouldn't be causing it.
The errors I do see in the messages log on Sept 7 all appear to be device based. I see a few failed scans which should only cause the system to repoll and not really cause that much extra load.
I see a few errors like this:
Bad get/set response (not matching) for 10.160.120.29,
with a few different IPs as well as
Sep 7 09:00:31 aqgwvc02 nbCaptureSensorGraph: Graph capture started: sensor=nbSNMPEnc1868EEA0_STATUS
Sep 7 09:00:31 aqgwvc02 nbCaptureSensorGraph: nbSensorGetUnresolvedFullLabel: invalid variable nbSNMPEnc1868EEA0_STATUS
Sep 7 09:00:31 aqgwvc02 nbCaptureSensorGraph: nbSensorGetUnresolvedFullLabel(ctx, nbSNMPEnc1868EEA0_STATUS, 1) failed,
where the nbSNMPEnc1868EEA0 is based on the device's mac address.
I can't say that any of these are actually causing the issue as I can't see what's happening during the hanging event.
I had noted before that speaking directly with tesch support may be your best alternative. Since you're in AU, I can't escalate to our engineering teams and have been asked that I allow the regional teams to do this. Additionally, local people may be able to remotely acces syour server should you allow it and getting in through the VM console, they may be able to get the capture logs while the system is in the hanging state. I can't give out the root password so we can't do that here.
I do understand that we've worked a lot here and you'd rather not go through the whole thing again but if you provide them the info on this post, I'd be happy to work with them and get them up to speed on the issue and work with them and engineering to see if we can't reach some kind of resolution.
Steve.
(CID:124525817)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:35 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steven.
As far as the logs are concerned, the file log file I created the morning after a reboot, time stamp of the archive is 7 September 2017 at 9:51am, reboot was performed the night before at 9pm on 6th September 2017. The second log file I created while the server was all locked up on 10th September 2017 at 8:52pm. Reboot was performed after I created those log files. What happens now after a reboot that never happened before is that we get about 10 device comms loss errors & then they quickly resolve, again I don't care about those as the server is probably polling when we reboot. Maybe explain the device errors.
As for the reboot process, we always do a client software reboot from the VM management software as again the DCE client is not responding/locked up.
Regardless of what day this happens, it is always at night after VM Ware tools has done its snapshot/disk consolidation/backup etc. I can only assume that DCE is NOT compatable with the VM tools/system that we run which seems a bit strange to me.
I intend to turn the backup snapshots off for a couple of weeks & see what happens, I guess if I perform a series of daily synchonised backups, at least our risks will be minimised.
I will try to log a job with APC/Schneider but as they earlier this year tried to price hike our support contract by $30K & we haven't payed up, I'm assuming, I'll get knocked back.
Thanks.
(CID:124525999)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:35 PM . Last Modified: 2024-04-07 11:43 PM
I am told by the VM people that this message keeps coming up on their logs:
Message from vpsuser
Install the VMware Tools package inside this
virtual machine. After the guest operating system
starts, select VM > Install VMware Tools… and
follow the instructions.
info
10/09/2017 8:59:13 PM
StruxureWareDCE
vpxuser
Obviously we can't do that as you stated, we would need the master password.
(CID:124526494)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:35 PM . Last Modified: 2024-04-07 11:43 PM
Hi Steven. Its been a week now & we have not seen any kick outs, log offs, unresponsiveness nor reboots required. We are currently just running a synchonised back up daily so again I can only put this down to that DCE is NOT compatable with the VM tools/system that we run. Snapshots/Disk cloning backups etc obviously interfere with its background processes. Given the amount of VM's out there, perhaps APC should really be looking at this?
We intend to wait a bit longer then make a decision on the way forward.
Thanks.
(CID:125209746)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:35 PM . Last Modified: 2024-04-07 11:42 PM
Hi Steven.
We had another lock-up/server becoming unresponsive instance last night. If you logged in via the client, it just sat there & the green bar did not move & if you tried the website, you just got the constant spinning wheel logo. I did try what you said & was able to get in & extract the capture logs before rebooting the server, which surprised me but it did work. Here they are, hope they give you some insight.
aqgwvc02.cems.citec.com.au_2017-09-10_20-52-26.tar.gz
(CID:124525411)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-03 09:36 PM . Last Modified: 2023-10-22 01:15 AM

This question is closed for comments. You're welcome to start a new topic if you have further comments on this issue.
Link copied. Please paste this link to share this article on your social media post.
You’ve reached the end of your document
Create your free account or log in to subscribe to the board - and gain access to more than 10,000+ support articles along with insights from experts and peers.
