
Ask our Experts
Didn't find what you are looking for? Ask our experts!
Schneider Electric support forum about installation and configuration for DCIM including EcoStruxure IT Expert, IT Advisor, Data Center Expert, and NetBotz
Search in
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:53 AM
We have had 2 DCE servers in the last 24 hours that suddenly started sending 1000's of alert emails out to all email recipients. I personally got over 50000 from them
We have seen this before on servers with high uptime (both of these were reporting 497 days uptime). Both are running on 7.4.3 of DCE. I was under the impression this issue had been resolved after 7.2.5, but I guess not.. All the emails report that the email is repeat number 32xxx - the last 3 digits seem to be different on each server.


None of the alert action are set to repeat. Due to our experience of seeing this issue before we set up the emails we receive to show the repeat number, since this seems to identify this specific issue is occurring
The emails are relating to historical events and it seems as though DCE is going through the whole history of alerts and resending emails for all of them.
In the past this has been resolved by rebooting the server.
However this did not work for one of them as the postgresql service would not start

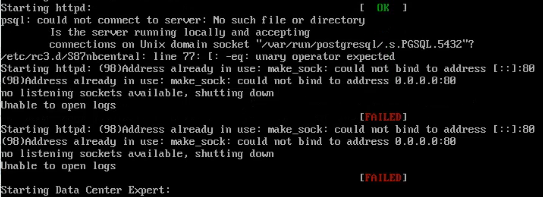
The capture logs showed that the var folder was full and since I had previously (luckily) been provided with the root password for this server I went through the procedure provide by Schneider to empty the logs from var/ folder. This was successful and the server restarted properly.
The second server did restart normally without needing the root password, which was lucky since I don't have the root password for that one!
So here come the questions:-
What causes the issue that makes DCE send out 1000's of emails?
Has this issue been resolved in 7.5.0?
Why does the var/ folder get filled up?
Is the issue regarding the var/ folder getting filled up resolved in 7.5.0?
Since the uptime was reporting as 497 days does this mean that when installing updates and the server says it is rebooting that it does ot really reboot the whole OS? I don't think it is 497 days since this server was updated to 8.4.3.
Most importantly:-
Can you provide the root password for the 2 other servers this customer has to allow us to get them back on line quicker? (I know you don't like to give these out but please note we are an Elite partner not an end user, and we just want to support our customers...)
What do we do if we see this issue again on a server we do not have the root password for? How do we get this issue resolved quickly? As a partner can you provide quick access to this type of requirement?
If I had not got the root password from a previous issue the server would have been offline for several hours whilst we tried to either get the root password or asked Schneider to correct the var/ folder issue. And at the end of all this we would have had an extremely unhappy customer..
If it helps I can provide the capturelogs etc for both servers.
(CID:134679635)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:53 AM
Hi Garry,
What I can tell you at the moment is that the issue with the /var folder getting filled up is resolved in DCE 7.5.0 so you should have those customers upgrade as soon as possible.
It would be good if you can share the capturelogs fro the two servers. I can contact you offline if need be.
Regards
(CID:134679683)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:53 AM
Hi Garry,
What I can tell you at the moment is that the issue with the /var folder getting filled up is resolved in DCE 7.5.0 so you should have those customers upgrade as soon as possible.
It would be good if you can share the capturelogs fro the two servers. I can contact you offline if need be.
Regards
(CID:134679683)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:53 AM
Thanks for the answers.
John, can you provide a link tot your Schneider box to uploads the logs files to please?
I believe you know this customer - Telstra, as the other Physical appliance had a similar issue recently that was resolved the same way.
I am being pressured now by the users of the servers to provide a report as to what went wrong...
(CID:134679738)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:53 AM
Hello, is this the same issue that John Benedict Tayao is working on from Telstra? They were reporting a performance issue under BFO case #51942729? If so, we mentioned the java process was high. There also may be an issue with a high volume of apache requests that could be affecting this too. If this is the same issue then I would work through John (Benedict Tayao) for updates.
(CID:134679792)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:53 AM
Josh
Not related. Didn't even know this was Telstra that Garry was talking about. I just responded on the /var full issue. Garry must be working on an issue that is at another part of Telstra I am not aware of. I work closely with the Telstra Australia DC team and they have upgraded all of their DCE's to 7.5.0 a couple of months ago.
Jim
(CID:134679852)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:29 AM . Last Modified: 2024-04-04 12:52 AM
Yes correct these servers are located in the UK and not really related directly to Telstra AU.
(CID:134679864)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:30 AM . Last Modified: 2024-04-04 12:52 AM
Okay, thank you for confirming that. Another issue from Telstra Australia had come up so just making sure that the two weren't connected.
(CID:134681219)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:30 AM . Last Modified: 2024-04-04 12:52 AM
Garry
You will most likely find that the upgrades will fail after the upload of the file from the client requiring you to power cycle the server to allow it to restart. I have seen this time and time again. What you will need to do is to create some space on the /var partition to allow the upgrades to work. You will find that the /var/log/atop directory contains around 3GB of log files which are not used. You can safely delete all of them once you obtain the root password from support. Anything higher than 7.2.7 does not have this issue as the 'cleanup' processes worked much better from then. Take it all the way up to 7.6.0 (as of yesterday) and you will get all the other fixes sorted out.
FYI - atop is similar to the linux top program that also writes daily log files and so fills up the /var partition which is only 4GB in size.
The 1000+ email issue was finally corrected in 7.5.0. As a workaround if you rebooted the server, the issue will stop for about 6 months before starting again.
Good luck and keep fighting those bugs...
Jim
(CID:134679689)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:30 AM . Last Modified: 2024-04-04 12:52 AM
Since both servers are at 7.4.3 should this cleanup process have prevented the issue in the first place?
(CID:134679741)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:30 AM . Last Modified: 2024-04-04 12:52 AM
Hello, version 7.4.3 was released in April 2017. If they upgraded around that time then that would follow the 497 day (1 year ~ 5 months) pattern and would be expected. If they had upgraded to 7.5.0 when it was released in January 2018, they would not have run into this bug related to the "1000's of emails" either. FYI, this bug (497 day - 1000's of emails) is not fixed in 7.4.3, 7.5.0, or 7.6.0 (released this past week). Trying to get this fixed as soon as possible since it comes up frequently.
(CID:134679791)
Link copied. Please paste this link to share this article on your social media post.
Link copied. Please paste this link to share this article on your social media post.
Posted: 2020-07-05 12:30 AM . Last Modified: 2023-10-22 01:27 AM

This question is closed for comments. You're welcome to start a new topic if you have further comments on this issue.
Link copied. Please paste this link to share this article on your social media post.
You’ve reached the end of your document
Create your free account or log in to subscribe to the board - and gain access to more than 10,000+ support articles along with insights from experts and peers.
